What I See Coming in LLM Reinforcement Learning
RL for LLMs is going to be a relevant and durable process for AI development so long as we don't have AGI.
Reinforcement Learning (RL) for LLMs seems to be a popular topic right now for those of us in the AI space; however, most of the world is completely unaware of how powerful RL is. This means we are really early and being really early means it is up to us to figure out how to get paid for out RL-related work!
Deploying an RL trained LLM
RL is a strategy for teaching an Agent to follow a policy that maximizes the Agent's expected rewards. RL environments are "worlds" that we create to let an agent interact with and receive rewards from. If you would like to teach an LLM to do a new task, one with a quantifiable score for "goodness", you might want to consider RL. At a high level:
- (Optional) Create a representative world that your LLM Agent can interact with.
- Accurately measure how much "good" your LLM is doing in the real/representative world.
- Maintain infrastructure that tells the LLM how good it is doing.
- (Optional) Provide a way for everyone else to talk to your LLM
I think this niche will be a very durable one (as durable as things can be in this rapidly changing field) plus it's super cool! If you don't consider me an authority, consider some RL opinions from prominent Twitter (X) users.
There are many write-ups and tutorials online for performing LLM RL. However, I'd like to do things that have economic value. Are there any analogies we can make to explore the market dynamics for developed/deployed LLM solutions?
Comparing LLM RL to Producer/Importer/Exporter Dynamics
This is a nascent industry. Maybe we can compare LLM Reinforcement Learning to the marketplace dynamics of international trade in the post-industrial revolution period. To make this comparison, we need to figure out a few things. What is the factory? What are the goods that a factory produces? Who are the factory owners? Who is managing imports & exports? What middle-men exist?
Here is how I think about it:
A factory can produce reinforcement fine-tuned models, fine-tuning datasets/RL traces, or RL environments. A dataset can be directly trained on; models and environments require an end-user to build an integration/knowledge extraction pipeline out of the produced good.
A factory can be an RL environment itself & its surrounding infrastructure. This means that a factory that produces RL environments is a factory producing factory. A factory can be some set of infrastructure that produces a workable RL environment (or set of environments). e.g., Use an emulator to play any Atari game out of a set of candidate games. There will be a lot of shared infrastructure from game to game. A factory can be an engineer/corporation a one-off environment. For example, you might have a solo engineer build out an environment for solving algebra problems.
There is definitely some overlap here. Let's visualize our value chain:
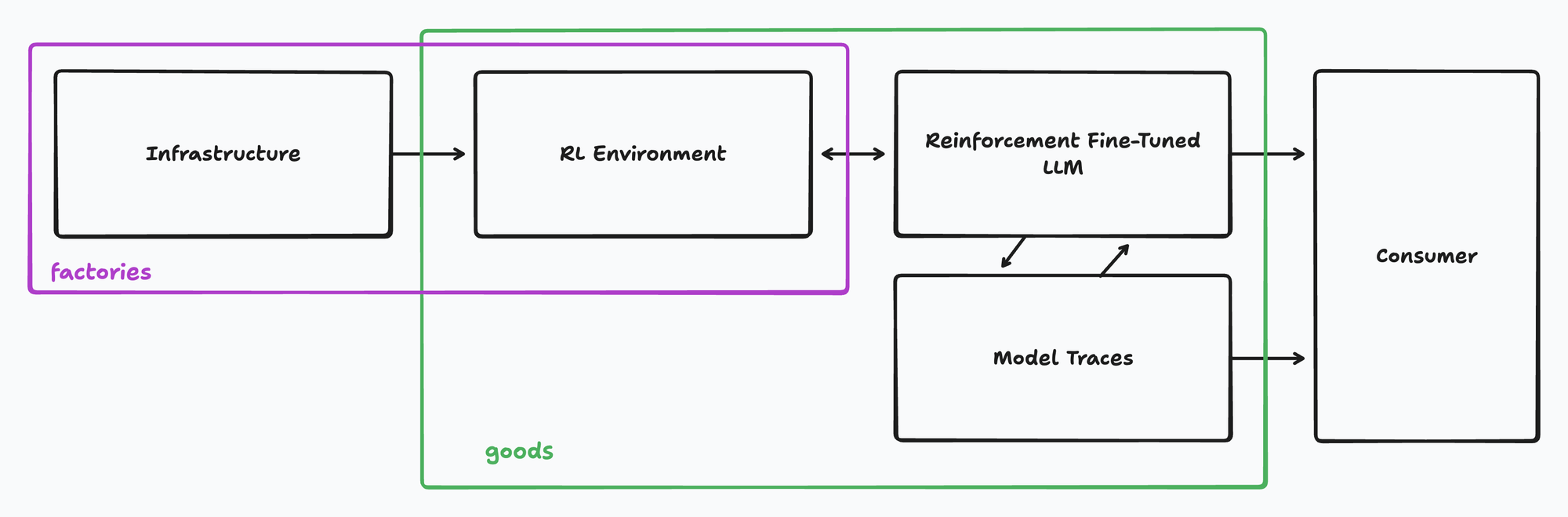
There is an opportunity for value creation on every box in the above diagram. There is an opportunity for value capture on every horizontal arrow in the above diagram.
How do we capture value?
Calaveras is an organization participating in this new economy. They sell datasets and offer RL environment creation as a service. There are more ways to capture value as well.
Sell the dataset
Like Calaveras, you can identify a dataset that makes an LLM good at task X. You should demonstrate this dataset improves LLM's performance. You can then sell the dataset to groups who want their LLM to be good at task X.
Lease the dataset
If you have an extremely valuable dataset you may be able to lease it out. However, I suspect you don't have Shutterstock levels of valuable data. This seems like a tricky way to try and capture value.
Sell the RL environment
Since RL environments are dataset factories, someone may be willing to buy your environment and produce the data themselves. You should demonstrate that "good" outcomes in your environment correspond to "good" outcomes in the real world. Your value proposition is saving the engineering effort in developing this environment. You should ensure that integration and use of the environment is simple.
Lease the RL environment
This is a pay-as-you-go model. This is useful for environments that you expect to change over time / need maintenance. Agentic search is an example. Search engine optimization is another example.
Prime Intellect talks about the sell, lease, open source tension during their Environments Hub announcement blog post.
Most current discussion around RL environments centers on a wave of startups whose business model is to build and sell them exclusively to a handful of large closed labs.
- Prime Intellect (source)
Prime Intellect's stated goal is to keep SoTA RL infrastructure Open Source, with Environments Hub being a key piece of this. However, we can see that the value of entities like Prime Intellect to an AI Lab is the standardization of an interface format between environment producers and environment consumers. This solves the issue of buyers being unwilling to do one-off integrations with environment producers. See an excerpt from an integration:
import os
from verifiers import load_environment
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.environ.get("OPENROUTER_API_KEY"),
)
env = load_environment(
"terminalbench-env",
dataset="...",
)
results = env.evaluate(
client=client,
model="openai/gpt-5-mini",
)After this, Prime Intellect can implement a per-evaluation fee against a given environment—possibly with revenue sharing.
Reiterating The Opportunity in LLM RL
Build datasets, build engines that build datasets, build engines that build dataset building engines. Make it easy for people to buy what you have. Check out The Landscape of Agentic Reinforcement Learning for LLMs: A Survey. This survey talks about the state of affairs and future research directions. Consider the relationship between this survey and my writing above to be something like this: They ask "what research is there to do?" and I ask "how might we monetize this research?"